



여기서 다루는 내용
· ETL Job 생성
· ETL Job 실행 및 결과 확인
· 마무리
AWS Glue 간단 사용기 - 1부
AWS Glue 간단 사용기 - 2부
AWS Glue 간단 사용기 - 3부
1부에서 MovieLens 에서 제공하는 오픈 데이터를 활용하여 간단하게 Glue Data catalog를 구축하는 시간을 가졌습니다.
이번 시간에는 생성된 Data catalog를 기반으로 ETL job을 실행해 보도록 하겠습니다.
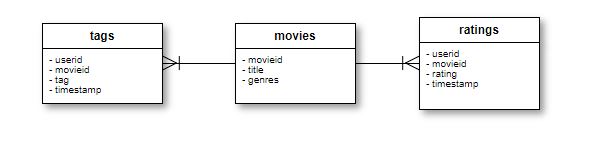
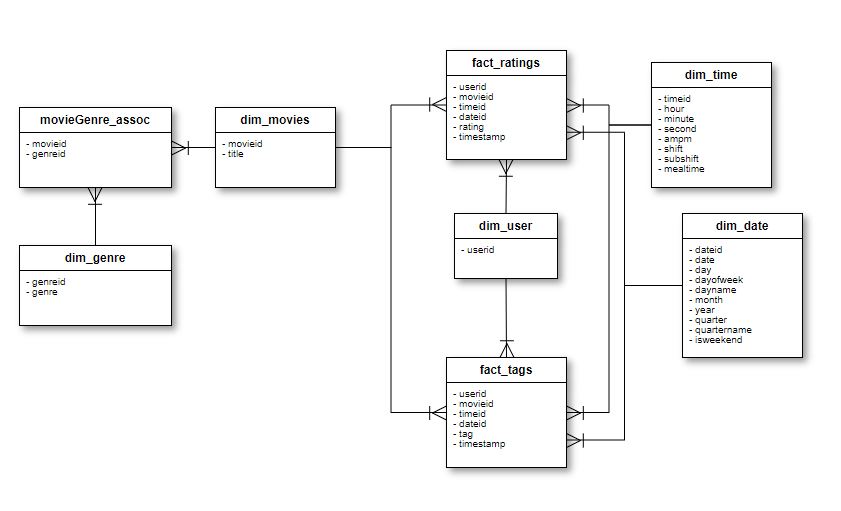
MovieLens 데이터 중 위의 movies, tags, ratings 테이블을 대상으로 아래 이미지와 같이 분석을 위해 디자인을 변경하여 두개의 팩트와 여러 차원으로 변경하는 작업을 ETL Job을 통해 수행 해보겠습니다.
ETL Job 생성
:: Jobs 생성
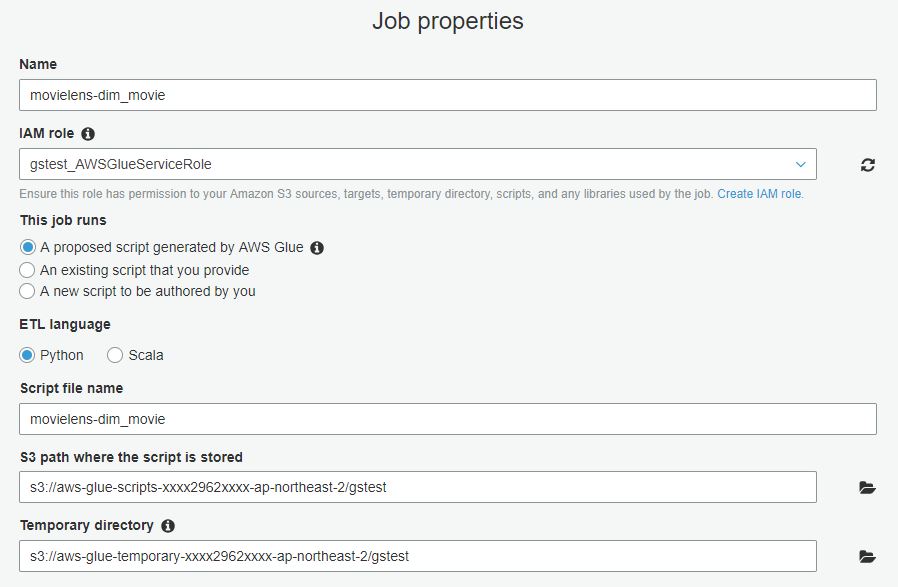
Add job을 눌러 Jobs 생성 화면으로 이동하여 Job Name을 입력하고 이전 시간에 생성한 IAM role 을 설정합니다.
ETL language는 Spark에서 지원하는 Python 또는 Scala를 선택합니다.
data source를 선택합니다.

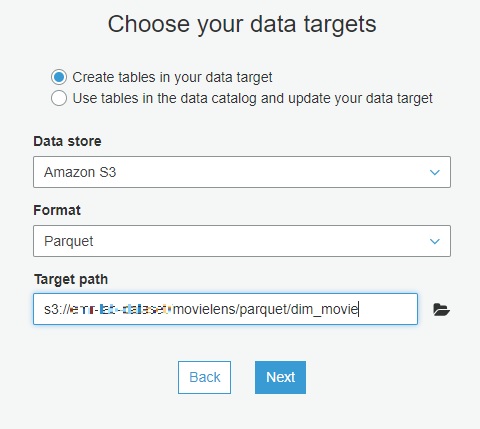
data target으로 S3를 선택하고, format을 parquet으로 선택합니다. (JDBC도 target으로 지원하며 여기서는 S3에 저장하도록 하겠습니다.)
data source의 컬럼과 target의 컬럼간 매핑을 설정합니다.

이후 최종적으로 save job and edit script를 선택하면 아래와 같이 스크립트를 수정하는 화면이 나옵니다.
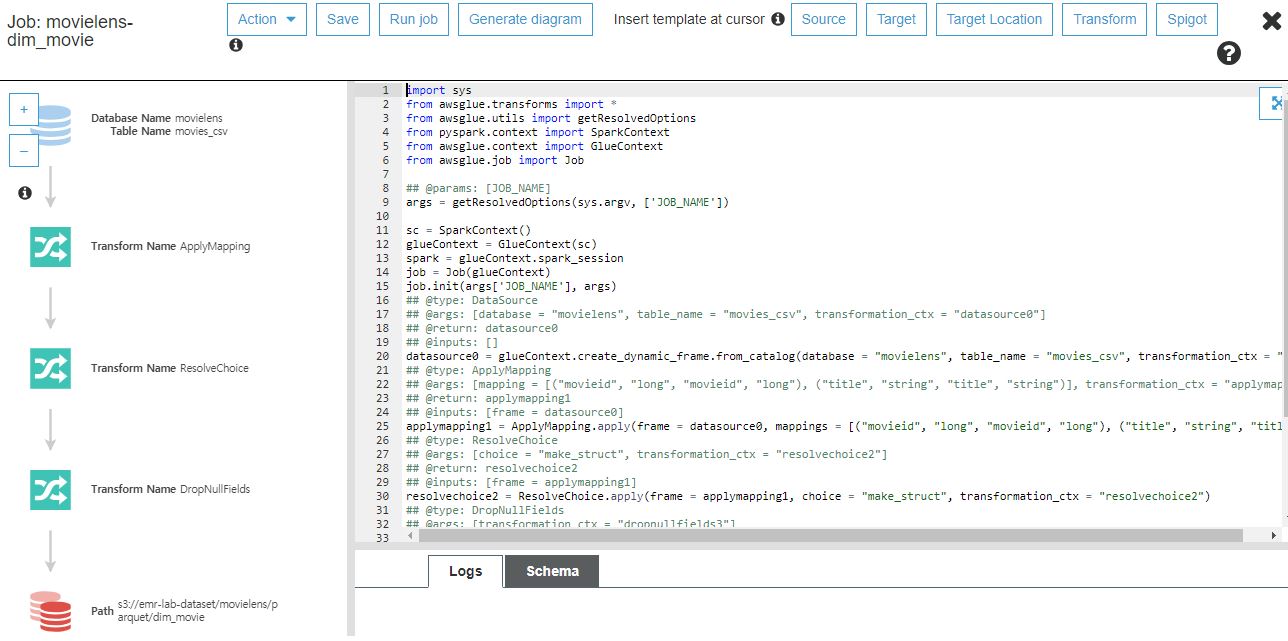
기존 Spark에서는 DataFrame을 사용하면 아래 코드와 같이 스키마를 지정해야 하지만
# Define schema
schema = StructType([
StructField("movieid", LongType(), True),
StructField("title", StringType(), True)
])
# Create dataframe
dimMovieDf = spark.createDataFrame(dimMovie, schema)
DynamicFrame을 사용할 경우 별도로 스키마를 추론할 필요가 없습니다.
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "movielens", table_name = "movies_csv", transformation_ctx = "datasource0")
그리고 여러 Built-in Transform을 사용하여 좀 더 수월하게 transform 할 수도 있습니다.
세부 내용은 여기 참고하시면 됩니다.
위에서 생성한 부분과 같이 job들을 생성합니다.
(여기서 단순하게 여러개의 job을 생성 하였지만 하나의 job에서 아래 작업을 처리 할 수 있습니다.)
:: Jobs 실행
Run job 을 실행하면 아래와 같이 history에서 실행 내역 확인이 가능합니다.
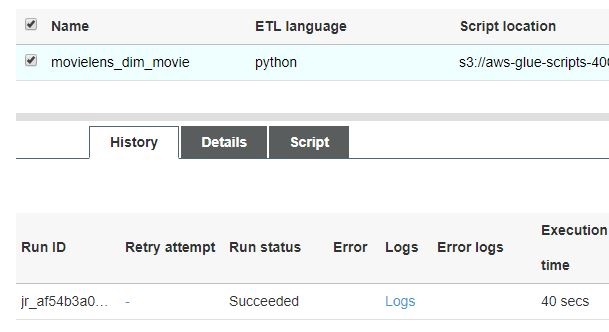
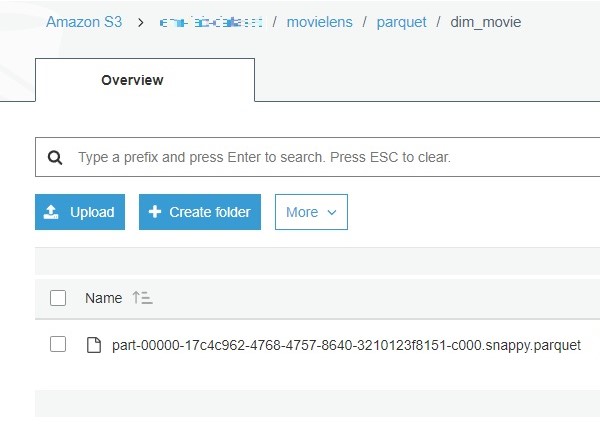
해당 S3 path에서 생성된 파일을 확인 가능합니다.
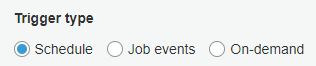
job trigger는 Schedule, Job events, On-demand 세가지 타입 중 하나로 선택 가능합니다.
자세한 내용은 여기 참고하여 아래 이미지와 같이 trigger를 생성하였습니다.

trigger 실행 후 job History를 확인해보면 Triggered by에 trigger 명이 나오는 부분 확인 가능합니다.

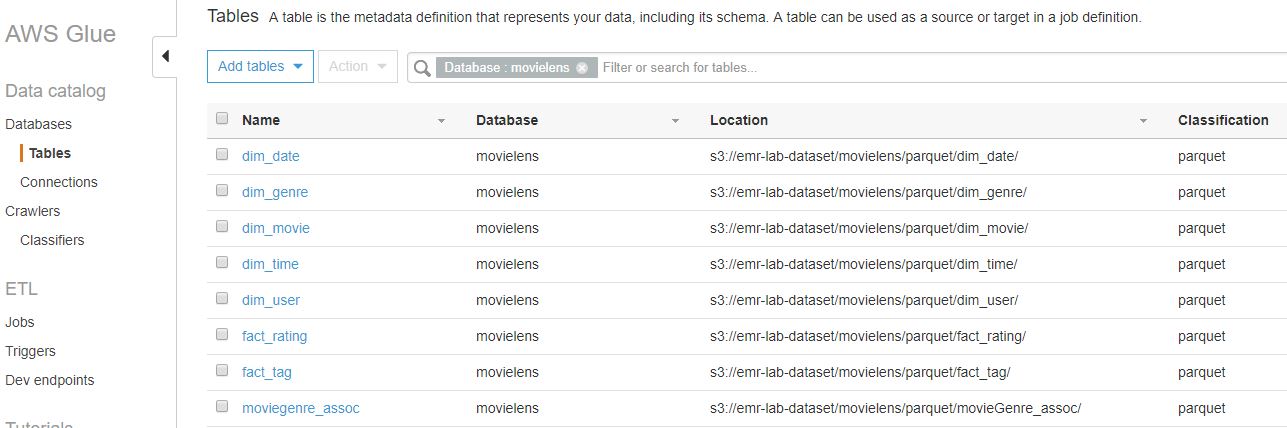
:: Data catalog 등록
마지막으로 Data catalog에 ETL Job을 통해 생성된 데이터를 등록하여 다른 AWS 서비스에서 Data catalog를 통한 분석이 가능하도록 합니다.
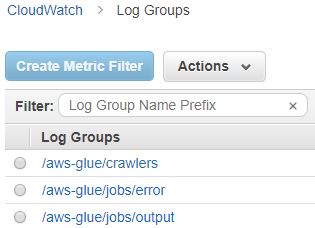
:: 로그 확인
Glue 로그는 CloudWatch Logs 에서 확인 가능합니다.
하지만 Log stream 이름을 알아야 되기 때문에 Job history에서 아래 이미지와 같이 Link를 눌러 CloudWatch로 이동 및 해당 job 로그 확인 가능합니다.
참고로 Logs link를 눌러 로그를 확인해보면 아래와 같은 spark-submit 로그를 확인할 수 있는데요.
/usr/lib/spark/bin/spark-submit --conf spark.hadoop.yarn.resourcemanager.connect.max-wait.ms=60000 --conf spark.hadoop.fs.defaultFS=hdfs://ip-172-31-19-158.ap-northeast-2.compute.internal:8020 --conf spark.hadoop.yarn.resourcemanager.address=ip-172-31-19-158.ap-northeast-2.compute.internal:8032 --conf spark.dynamicAllocation.enabled=true --conf spark.shuffle.service.enabled=true --conf spark.dynamicAllocation.minExecutors=1 --conf spark.dynamicAllocation.maxExecutors=18 --conf spark.executor.memory=5g --conf spark.executor.cores=4 --name tape --master yarn --deploy-mode cluster --jars /opt/amazon/superjar/glue-assembly.jar --files /tmp/glue-default.conf,/tmp/glue-override.conf,/opt/amazon/certs/InternalAndExternalAndAWSTrustStore.jks,/opt/amazon/certs/rds-combined-ca-bundle.pem,/opt/amazon/certs/redshift-ssl-ca-cert.pem,/tmp/g-7f8ef0ca97be890a82757382373cf019b788be65-6391259768151903352/script_2018-05-25-04-50-37.py --py-files /tmp/PyGlue.zip --driver-memory 5g --executor-memory 5g /tmp/runscript.py script_2018-05-25-04-50-37.py --JOB_NAME movielens_fact_rating --JOB_ID j_d4b9ef34175292f078a29b69d4d4ea2140a0bb8b5bf10bf0c44f7d2bababe336 --JOB_RUN_ID jr_d594743784ec26c30d69e6db9fae6b39a7baa8d848811c467574b8cd8a89e898 --job-bookmark-option job-bookmark-enable --TempDir s3://aws-glue-temporary-000000000000-ap-northeast-2/gstest
아래와 같은 spark submit 설정 값을 확인 할 수 있습니다.
--conf spark.dynamicAllocation.enabled=true
--conf spark.dynamicAllocation.minExecutors=1
--conf spark.dynamicAllocation.maxExecutors=18
--conf spark.executor.memory=5g
--conf spark.executor.cores=4
--driver-memory 5g --executor-memory 5g
Apache Spark는 기본적으로 모든 작업을 메모리에서 수행합니다. AWS Glue 처럼 Cluster mode에서 작동하는 Apache Spark의 경우 하나의 Driver와 여러 Executor 가 있습니다.
Driver, Executor 메모리의 제약이 있으므로 취급하는 데이터 크기가 큰 경우 메모리 부족에 주의해야 합니다.
예를 들어, driver 메모리 제약으로 인해 에러가 발생되고 Job이 실패할 수 있습니다. Job fail error 로그를 확인해 보면 아래와 같은 내용을 접할 수 있습니다.
An error occurred while calling o72.pyWriteDynamicFrame. Job aborted due to stage failure: Task 5 in stage 7.0 failed 4 times, most recent failure: Lost task 5.3 in stage 7.0 (TID 59, ip-172-31-60-131.ap-northeast-1.compute.internal, executor 8): ExecutorLostFailure (executor 8 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
마무리
이번 시간에는 ETL job을 통해 데이터 transform을 하고, 이를 Glue 데이터 카탈로그에 등록하였습니다.
다음 시간에는 이번 시간에 등록한 Glue data catalog 테이블을 다른 AWS 서비스에서 확인해보는 시간을 갖도록 하겠습니다.
AWS Glue 간단 사용기 - 1부