



여기서 다루는 내용
· 서비스 간단 소개
· Dataset 준비
· Glue Data catalog 구축
· 마무리
AWS Glue 간단 사용기 - 1부
AWS Glue 간단 사용기 - 2부
AWS Glue 간단 사용기 - 3부
AWS Glue가 이제 서울 리전에서 사용 가능하기 때문에 이 서비스를 간단하게 사용해보는 포스팅을 준비했습니다.
이번 시간에는 MovieLens 에서 제공하는 오픈 데이터를 활용하여 간단하게 Glue Data catalog를 구축하는 시간을 갖고,
2부에서는 생성된 Data catalog를 기반으로 ETL job을 수행하고, 3부에서는 ETL job에서 변환한 데이터를 다른 AWS 서비스에서 확인해 보도록 하겠습니다.
서비스 간단 소개
- AWS Glue
- 클라우드 데이터 추출, 변환 및 로드 (ETL) 서비스
- 서버리스 기반 완전 관리형 서비스
- 크롤러를 통한 자동 스키마 검색
- 통합된 데이터 카탈로그 제공
- 개발용 엔드 포인트 및 노트북(Notebooks) 제공
- Scala, Python 언어 및 Apache Spark용 ETL Job 코드 생성 및 스케줄 실행
- 단일 DPU : 4vCPU 및 16GB Memory 제공
- 크롤러, ETL 작업 및 개발용 엔드 포인트 모두 DPU 시간당 0.44$로 초 단위 청구
- 제품 세부 정보 : Link
Dataset 준비
:: MovieLens
MovieLens라는 영화 평가 오픈 데이터 세트를 다운 받습니다.
데이터 세트의 정보는 아래와 같습니다.
Full: 26,000,000 ratings and 750,000 tag applications applied to 45,000 movies by 270,000 users. Includes tag genome data with 12 million relevance scores across 1,100 tags. Last updated 8/2017.
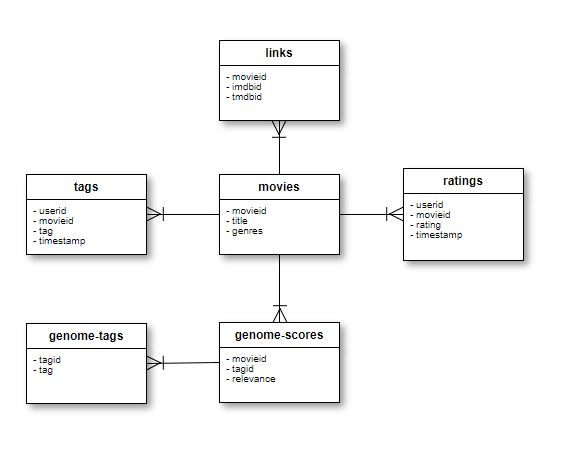
해당 데이터 세트 링크는 여기 참고 바랍니다.
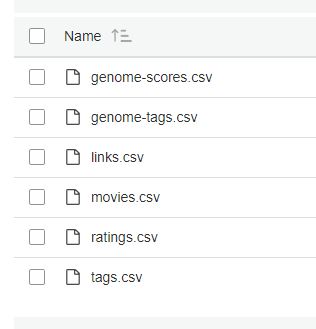
임의의 S3 버킷을 생성하여 해당 버킷에 데이터를 업로드합니다. 모두 CSV 형식으로 되어 있으며 구분자는 Comma(,) 로 되어있습니다.
Glue Data catalog 구축
:: Glue Role 생성
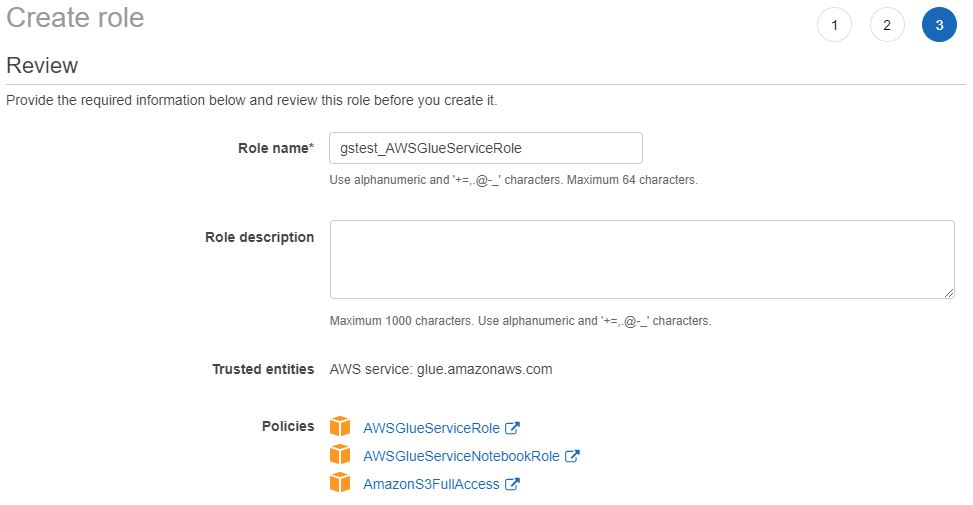
먼저 아래 policy가 포함된 Glue role을 생성합니다.
- AWSGlueServiceRole
- AWSGlueServiceNotebookRole
- AmazonS3FullAccess
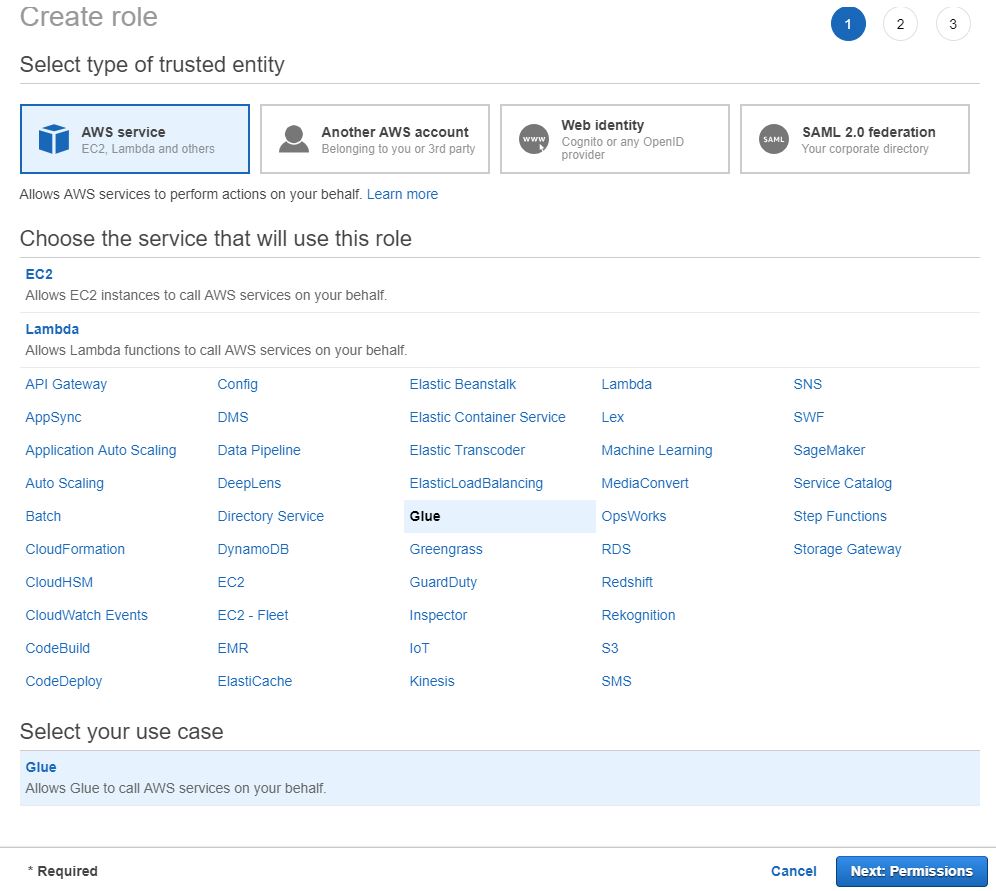
:: Crawler 생성
crawler 이름을 넣습니다.
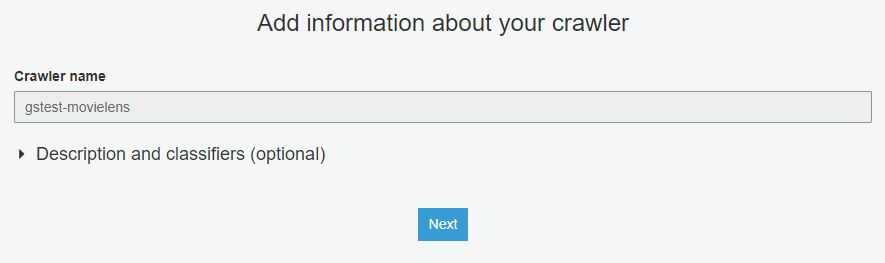
data store로 JDBC 또는 S3 선택이 가능합니다. 여기서는 S3 를 선택하고 해당 path를 설정 합니다.
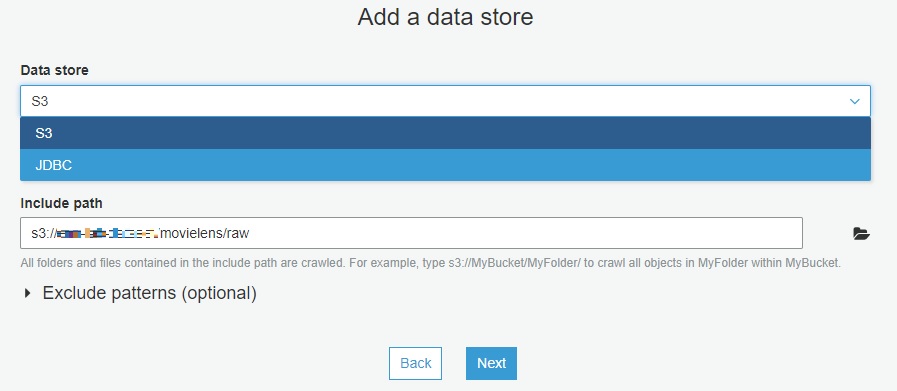
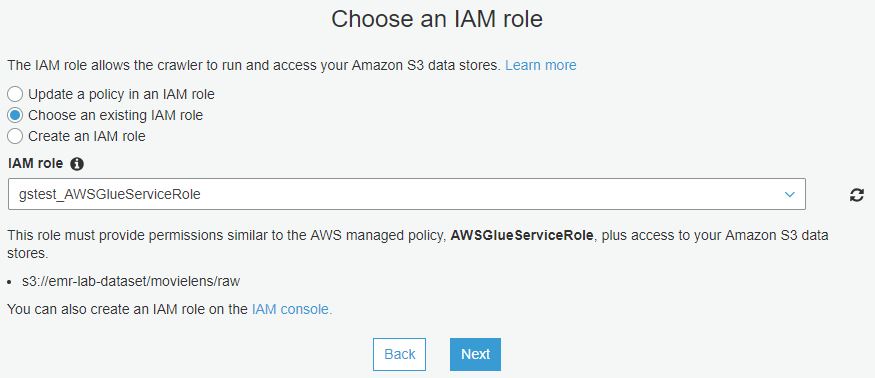
앞서 만들었던 role을 선택합니다.
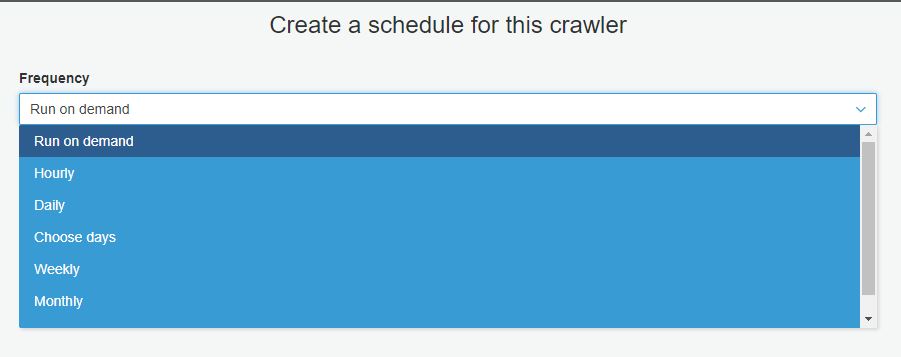
crawler 실행 빈도를 선택합니다. (Run on demand 부터 기타 cron 형식 실행까지 표현 가능합니다.)
Add database를 눌러 Database 생성 후 해당 Database를 선택합니다.
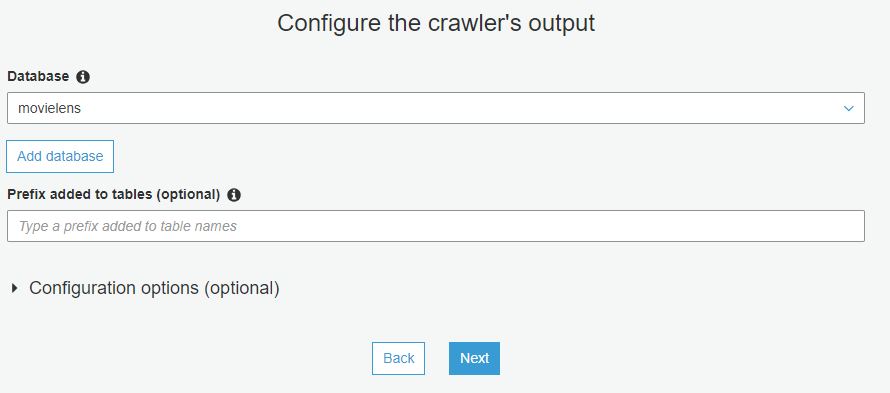
Finish를 눌러 crawler를 생성합니다.
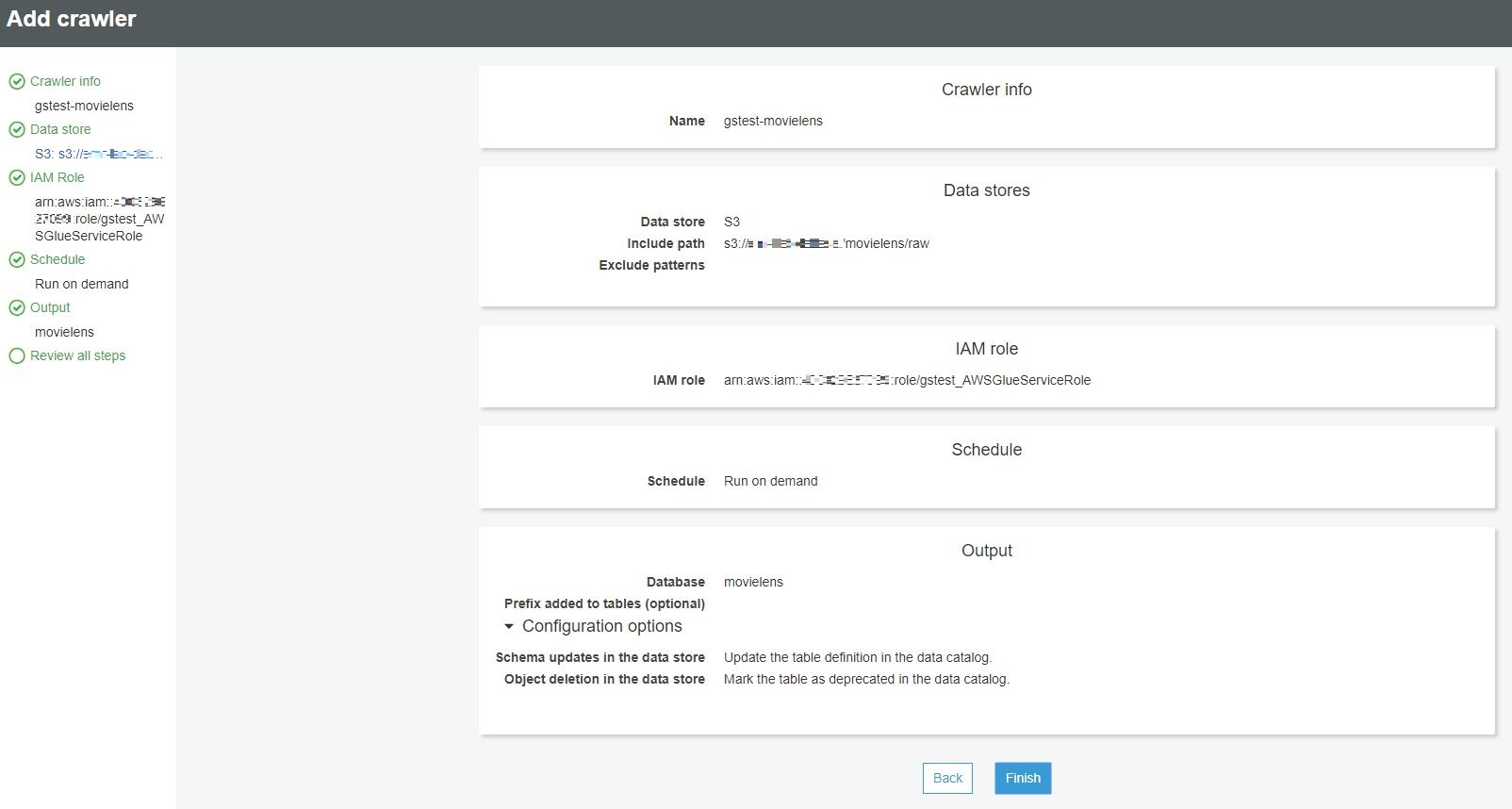
생성 되면 아래와 같이 Status가 Ready 상태인 crawler가 보입니다.

:: Crawler 실행
Built-in Classifier에서는 CSV를 포함하여 Parquet, ORC, xml, json, Apache log 등의 타입들을 지원하기 때문에 Run crawler를 눌러 실행합니다.
※ 참고 : CSV 같은 경우 아래와 같은 구분자를 지원합니다. => Comma (,) , Pipe (|), Tab (t), Semicolon (;), Ctrl-A (u0001)
classifier에 대한 자세한 내용 및 별도의 custom classifier 가 필요한 경우 여기 참고 바랍니다.
실행이 완료되면 실행 시간이 표시되며 업데이트 또는 추가된 테이블들을 확인 가능합니다.
아래 이미지에서는 crawler가 22초의 수행 시간이 소요되었고, 6개의 테이블을 추가하였습니다.

Data catalog에 movielens database에 생성된 테이블을 확인해보면 아래와 같이 생성 된 것을 확인 가능합니다.
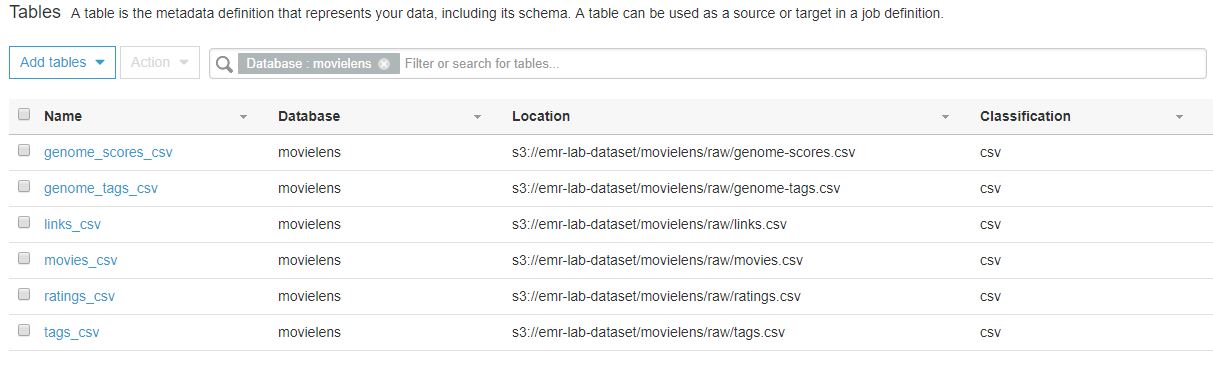
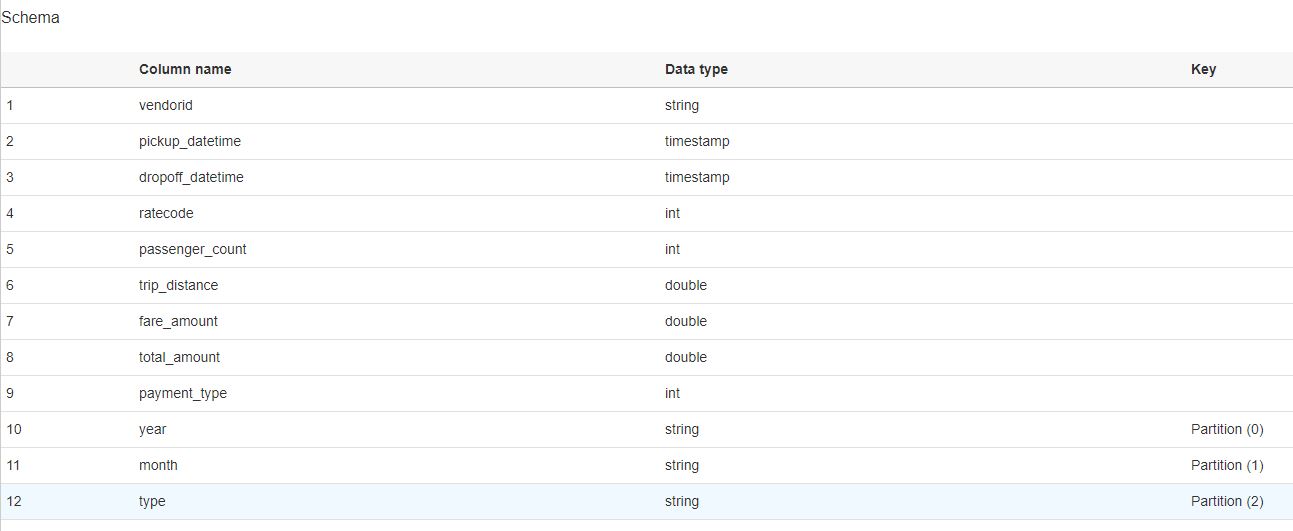
movie 테이블을 선택하여 세부 내용을 확인해보면 테이블 정보와 schema를 확인해볼 수 있습니다.
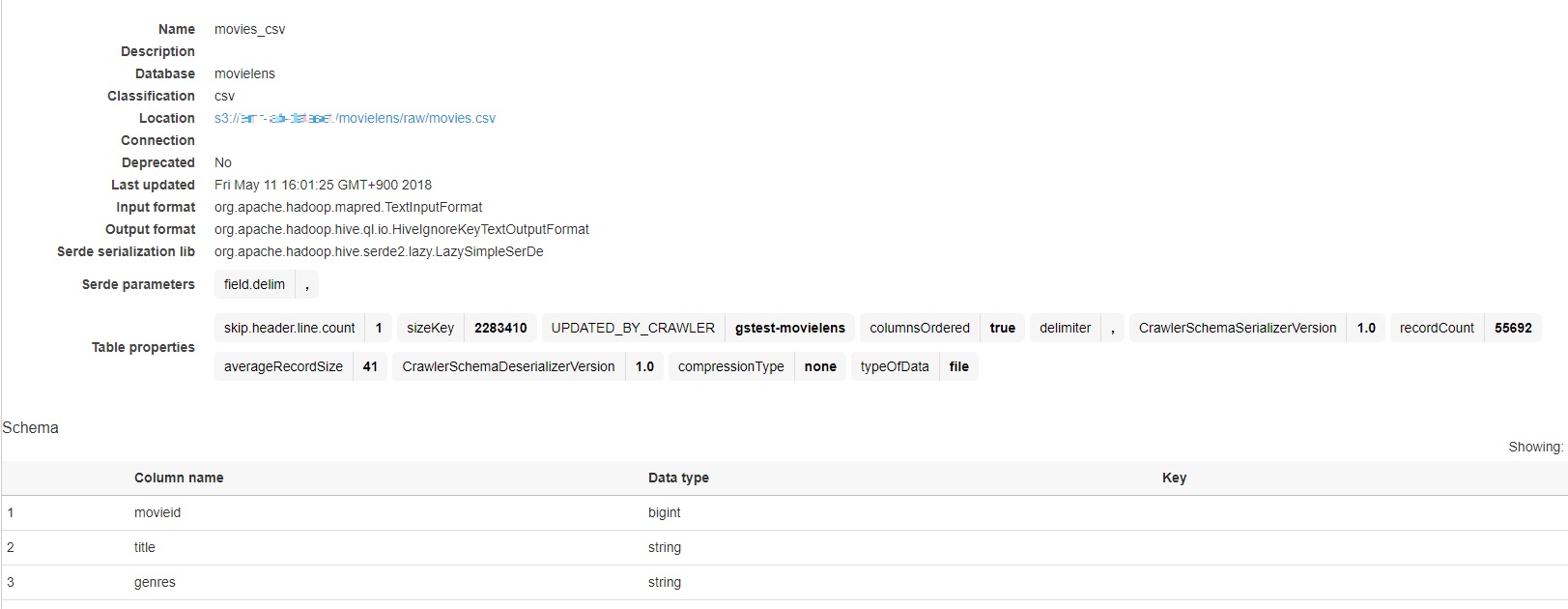
※ 참고 : partition 된 데이터 같은 경우 아래 이미지와 같이 Key 부분에 Partition 이라고 표시 됩니다.
자세한 내용은 여기 참고 바랍니다.
마무리
이번 시간에는 crawler를 사용하여 Glue 데이터 카탈로그를 만들어 봤습니다.
다음 시간에는 생성한 데이터 카탈로그를 기준으로 ETL job을 생성하여 실행해 보는 시간을 갖도록 하겠습니다.