



여기서 다루는 내용
· 간단 소개
· 사전 준비
· 연동 확인
· 마무리
이번 시간에는 BI Tool인 Apache Superset을 사용하여 AWS EMR 클러스터의 presto를 연동하여 데이터를 시각화를 간단히 해보도록 하겠습니다.
Apache Superset은 Python으로 만들어진 응용 프로그램 프레임워크인 Flask로 만들어졌습니다.
Cloud-native하고, Airbnb에서 아래와 같이 사용중이라 하니 검토해볼만 합니다.
“Superset is battle tested in large environments with hundreds of concurrent users. Airbnb’s production environment runs inside Kubernetes and serves 600+ daily active users viewing over 100K charts a day.”
- 원문
먼저 EMR 클러스터와 Superset을 준비하고, 샘플 데이터를 Hive 카탈로그에 등록하여 이를 Presto에서 간단 조회합니다.
그리고 Superset에 EMR의 presto에 연동하여 간단한 시각화를 해보겠습니다.
간단 소개
- AWS EMR
- 관리형 하둡 클러스터 플랫폼
- Apache Spark, HBase, Presto, Hive와 같이 널리 사용되는 분산 프레임워크를 실행
- Amazon S3 및Amazon DynamoDB와 같은 다른 AWS 데이터 스토어의 데이터와 상호 작용
- 수동 또는 Auto Scaling을 통한 인스턴스 수를 늘리거나 줄일 수 있으며, spot 인스턴스 활용을 통한 비용 절감 가능
- 제품 세부 정보 : Link
- Apache Superset
- Apache Incubating Project
- Airbnb에서 오픈소스로 공개한 BI Tool
- 고가용성 설계 및 대규모 분산 환경 수평 확장 설계 가능
- Dashboard 생성 및 공유 가능
- SQLAlchemy를 통한 database 연결
- 제품 세부 정보 : Link
- Github: Link
- AWS EMR
사전 준비
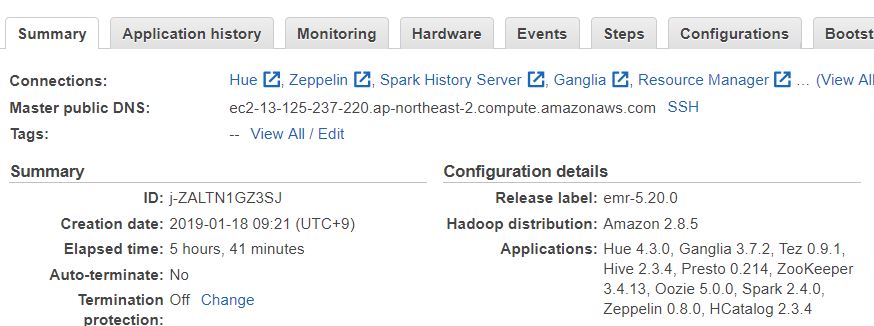
:: EMR 클러스터 생성
Hive, Presto가 포함된 EMR 클러스터를 생성합니다.
:: Apache Superset 준비
Superset은 EC2 Amazon Linux에 설치가능하며 Docker 환경을 지원합니다.
Apache Superset 공식 설치 및 설정 가이드 문서를 참고하여 설치를 합니다.
설치 완료 후 8088 port로 접근하면 아래 이미지와 같이 로그인 화면을 볼 수 있습니다.
:: 샘플 데이터 준비
본 포스팅에서는 샘플 데이터를 S3에 업로드하여 조회해보겠습니다.
먼저 movielens에서 latest datasets 데이터를 다운로드 받습니다.
압축을 해제하면 README.txt 파일 및 CSV 파일들이 보입니다.
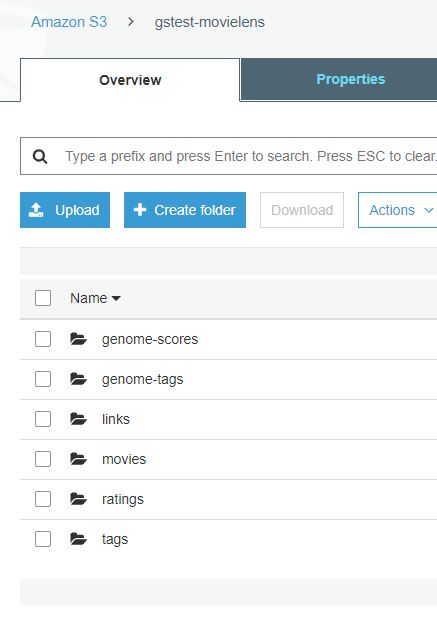
README.txt, genome-scores.csv, genome-tags.csv, links.csv, movies.csv, ratings.csv, tags.csv
S3에 해당 CSV 파일에 해당되는 각각의 폴더를 생성하여 업로드 합니다.
:: Hive 테이블 생성
위에서 업로드한 샘플 데이터에 대해 Hive 테이블을 생성합니다.
README.txt 파일을 참고하여 생성합니다.
:: Presto 조회
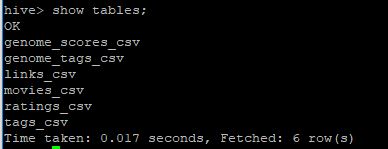
Presto-cli에서 Hive catalog 를 조회합니다.
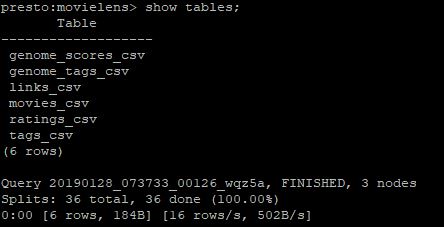
테이블의 데이터 조회도 한번 해봅니다.
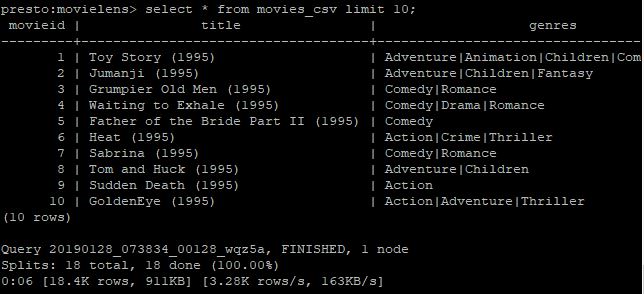
연동 확인
:: Superset Database 등록
Superset Web UI 상단에서 Sources를 눌러 Databases를 클릭합니다.
우측 상단 + 아이콘 버튼을 눌러 새로운 Database 등록 페이지로 이동합니다.

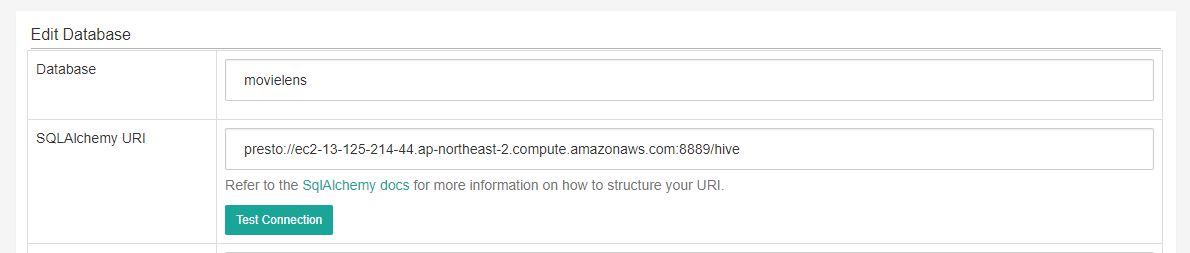
Database 명을 입력하고 SQLAlchemy URI를 입력합니다.
SQL Lab 사용을 위해 Expose in SQL Lab을 체크합니다.
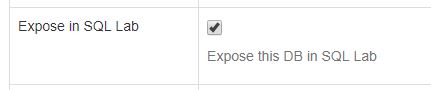
하단 Save 버튼을 눌러 movielens Database 등록을 완료 합니다.

:: Superset 테이블 등록
Superset Web UI 상단에서 Sources를 눌러 Tables를 클릭합니다.
우측 상단 + 아이콘 버튼을 눌러 새로운 Tables 등록 페이지로 이동합니다.
해당하는 정보를 넣고 테이블을 등록합니다.
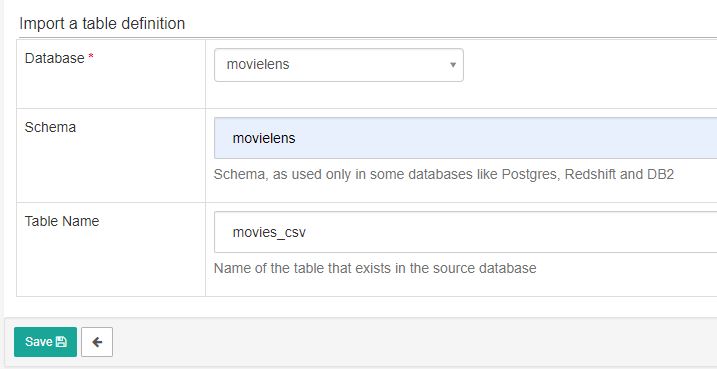
하단 Save 버튼을 눌러 table 등록을 완료 합니다.

나머지 table 들도 등록 합니다.
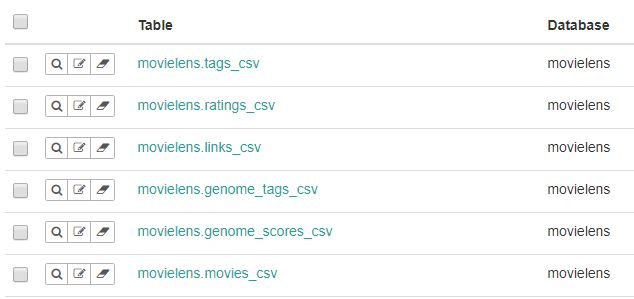
데이터 조회 및 Dashboard 생성
:: Dashboard 생성
Superset Web UI 상단에서 Dashboards를 누릅니다.
우측 상단 + 아이콘 버튼을 눌러 새로운 Dashboard 생성 페이지로 이동합니다.
Title 및 기타 정보를 입력하고 Save 버튼을 누릅니다.

:: Chart 생성
Superset Web UI 상단에서 Charts를 누릅니다.
우측 상단 + 아이콘 버튼을 눌러 새로운 Chart 등록 페이지로 이동합니다.
datasource 및 visualization type을 선택합니다.
여기서는 위에서 생성한 tags_csv 테이블을 선택합니다.
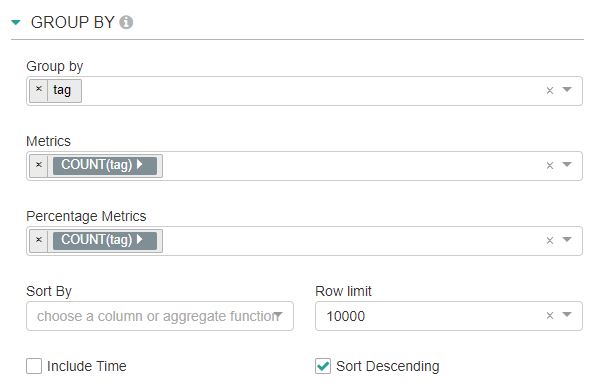
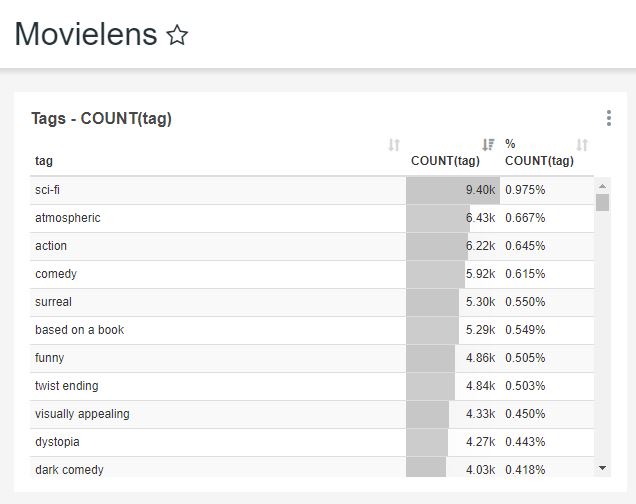
GROUP BY에 tag를 선택하여 tag별 개수를 확인해보겠습니다.
Group by에 tag를 선택하고 Metrics에는 COUNT(tag)를 Percentage Metrics에도 COUNT(tag)를 선택 합니다.
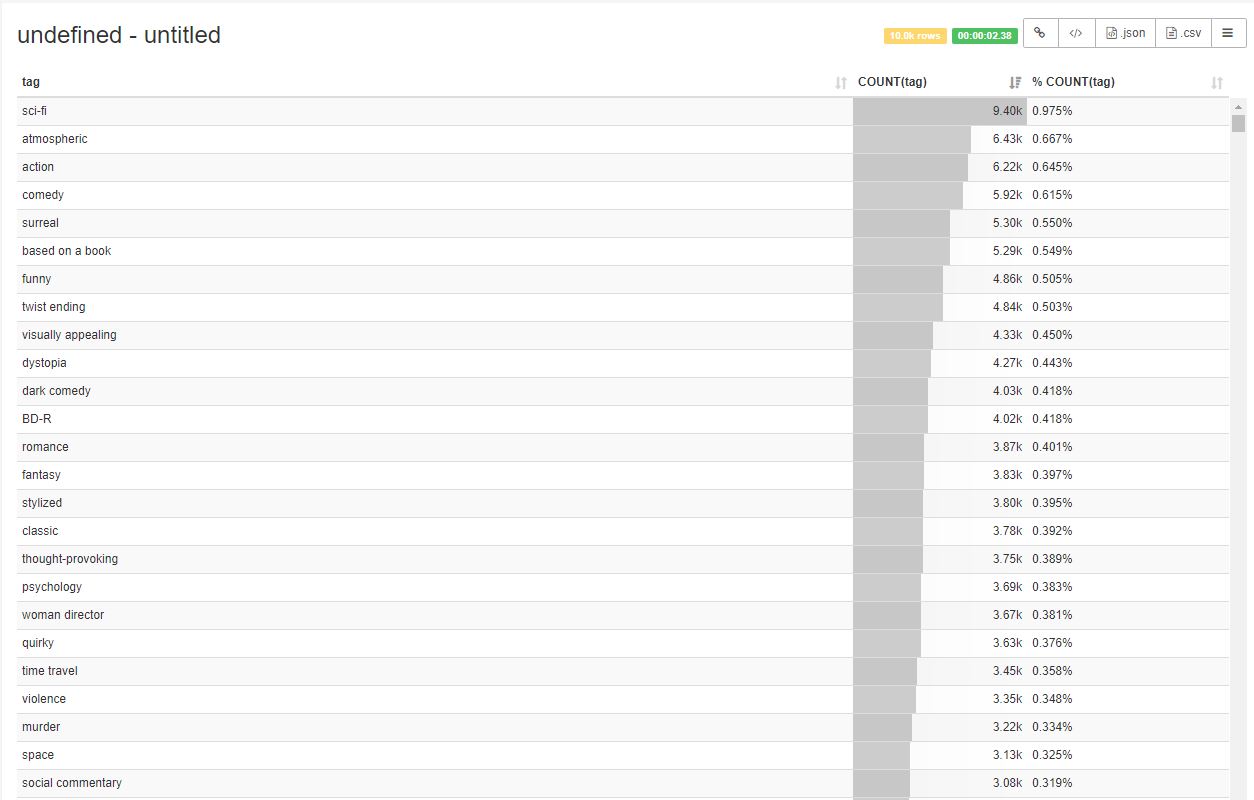
좌측 상단 Run query를 눌러 실행하니 아래 그림과 같이 결과가 나옵니다.
좌측 상단 Save 버튼을 눌르면 chart 저장 팝업이 생성됩니다.
chart 제목과 위에서 생성한 dashboard를 선택합니다.
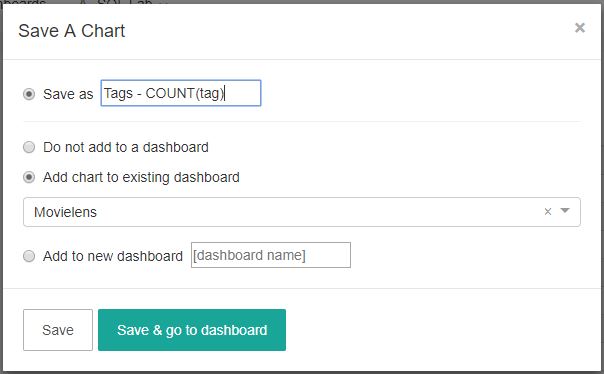
Save & go to dashboard를 눌러 저장한 dashboard로 이동합니다.
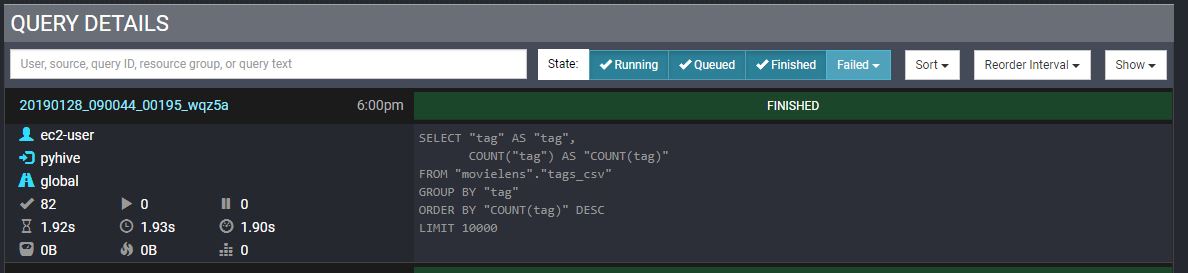
Presto UI로 잠시 이동해서 확인해보면 Superset에서 presto에 쿼리한 부분이 확인됩니다.
:: SQL Lab 쿼리 생성
Superset 에서는 SQL Editor를 사용해서 데이터 조회를 지원합니다.
Superset Web UI 상단에서 SQL Lab을 누르고 SQL Editor를 클릭합니다.
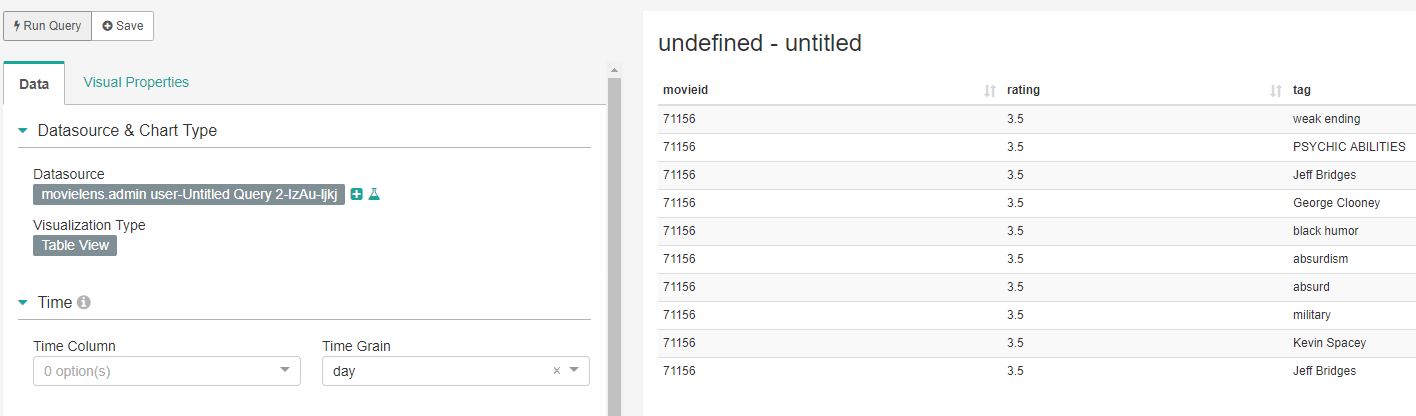
SQL 문을 입력하고 Run Query를 눌러 쿼리가 가능합니다.
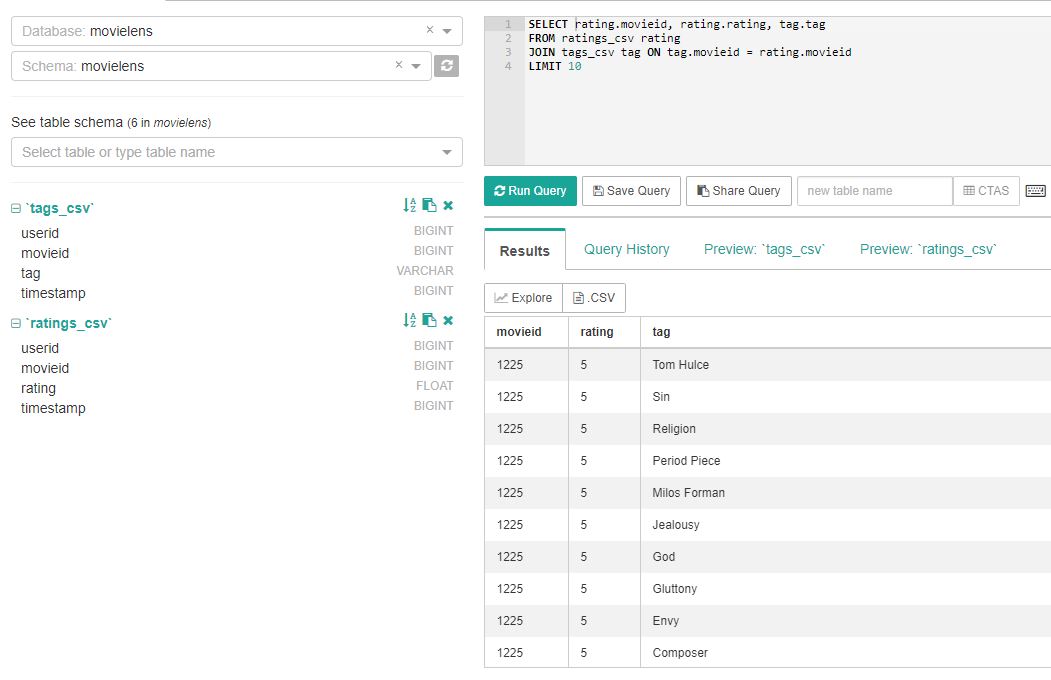
Explore를 눌러 해당 쿼리를 Chart 형식으로 추가하여 시각화 할 수도 있습니다.
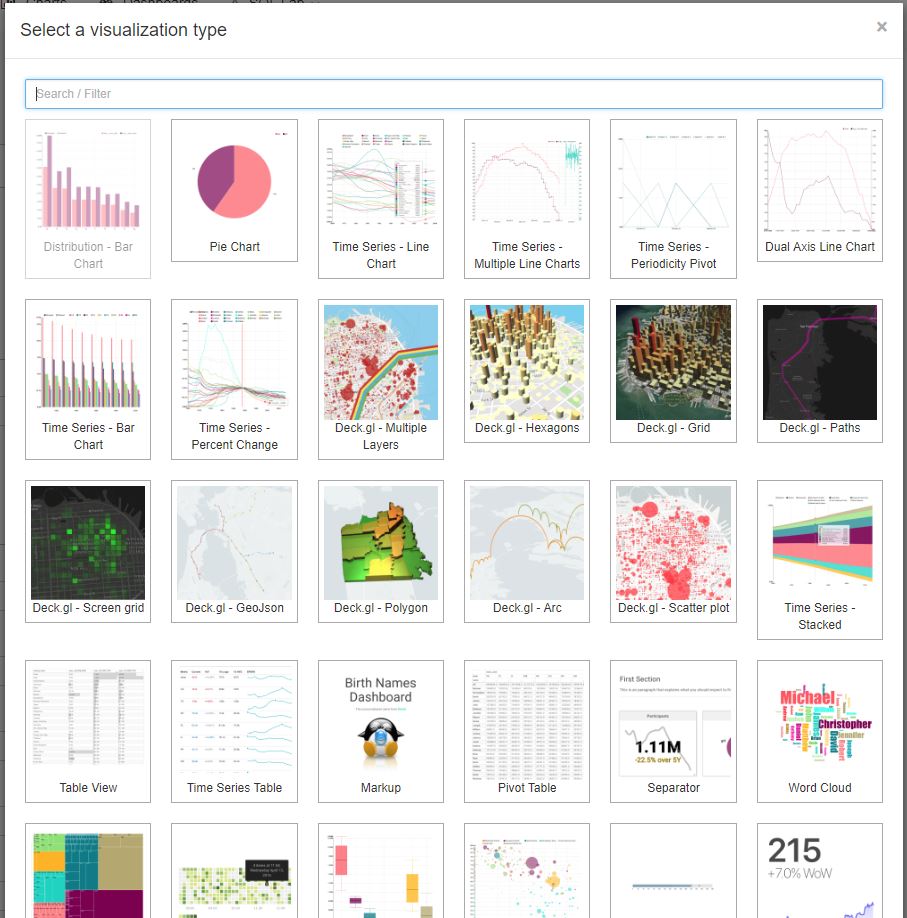
아래 이미지와 같이 visualization type을 눌러 원하는 type을 선택하여 시각화가 가능하며, 해당 chart를 dashboard에 등록할 수 있습니다.
마무리
Superset이 OSS이기 때문에 비용적인 측면에서 메리트가 있습니다.
이상으로 Superset에서 AWS EMR의 presto를 통해 데이터를 조회 및 간단 시각화 해 보았습니다.